
Como montar um pipeline de Terraform no Azure DevOps
Você sabe qual a melhor maneira de criar um pipeline para provisionar seus ambientes de nuvem com Terraform no Azure DevOps? Neste post vou mostrar algumas dicas para montar seu pipeline de maneira simples e eficaz.
Introdução
O Terraform é uma ferramenta que permite provisionar recursos de infraestrutura em diversos provedores de nuvem, como AWS, Azure, GCP, entre outros, usando uma técnica conhecida como Infraestrutura como Código (IaC). Ao usar uma ferramenta de IaC, você obtém diversos benefícios, como:
- Reprodutibilidade: você pode provisionar o mesmo ambiente quantas vezes quiser, sem se preocupar com erros humanos;
- Versionamento: você pode versionar seu código e controlar as mudanças de infraestrutura ao longo do tempo;
- Colaboração: você pode trabalhar em equipe e compartilhar o código de infraestrutura com outras pessoas;
- Auditoria: você pode auditar as mudanças de infraestrutura e saber quem fez o que, quando e por quê.
Como você pode imaginar, esses benefícios são potencializados quando você integra seus scripts Terraform a uma ferramenta de DevOps como o Azure DevOps. Mas você sabe como fazer isso?
Naturalmente, há diversas maneiras diferentes de resolver este problema. Vou mostrar aqui uma delas - que é a que usamos na CloudMotion para provisionar os ambientes de Azure de nossos clientes.
Neste post eu assumo que você já conhece Terraform e sabe como criar seus próprios scripts. Se não, sugiro que você dê faça este tutorial de Terraform antes de seguirmos.
Criando um pipeline de Terraform no Azure DevOps
Para o exemplo a seguir montei um estudo de caso baseado na empresa fictícia Fabrikam Fiber:
A Fabrikam Fiber é uma operadora de tevê a cabo e internet, que mantinha seu site institucional em WordPress numa VM Linux com Apache. Agora, para tirar melhor proveito da nuvem e reduzir seus custos com administração e operação do ambiente, a equipe de sustentação do site decidiu utilizar o Azure App Service para hospedar o site. Aproveitando para “colocar a casa em ordem”, a equipe decidiu já criar o novo ambiente utilizando boas práticas de IaC e DevOps.
Organização do código
Tudo começou com o repositório no Azure DevOps. É uma boa ideia criar um repositório para cada recurso de alto nível que você pretende provisionar. “Recurso de alto nível” é um conjunto de recursos que operam em conjunto para atender a uma finalidade específica. No nosso exemplo, o “recurso de alto nível” é o site institucional em WordPress. Num nível mais baixo, esse recurso é composto de vários outros recursos (App Service, MySQL, Redis…) e pode estar provisionado em múltiplos ambientes (Dev, QA, Prod…).
Sendo assim, criamos um novo repositório exclusivo para o código IaC do site:
Note que apliquei aqui um padrão de nomenclatura que gosto de usar: o nome do nosso recurso (“corpsite”) e o sufixo infra para indicar que é um repositório de infraestrutura.
É sempre uma boa ideia preencher o README com informações a respeito do ambiente que vai ser provisionado, incluindo dicas e sugestões para futuras manutenções e/ou provisionamentos:
Depois disso, iremos criar pastas para organizar nossos arquivos. Teremos pastas separadas para os modelos do Azure DevOps, para o script Bicep (falaremos mais sobre ele) e para os scripts Terraform. Por fim, criaremos na raíz do repositório nosso arquivo de pipeline.
Você deve ficar com algo assim:
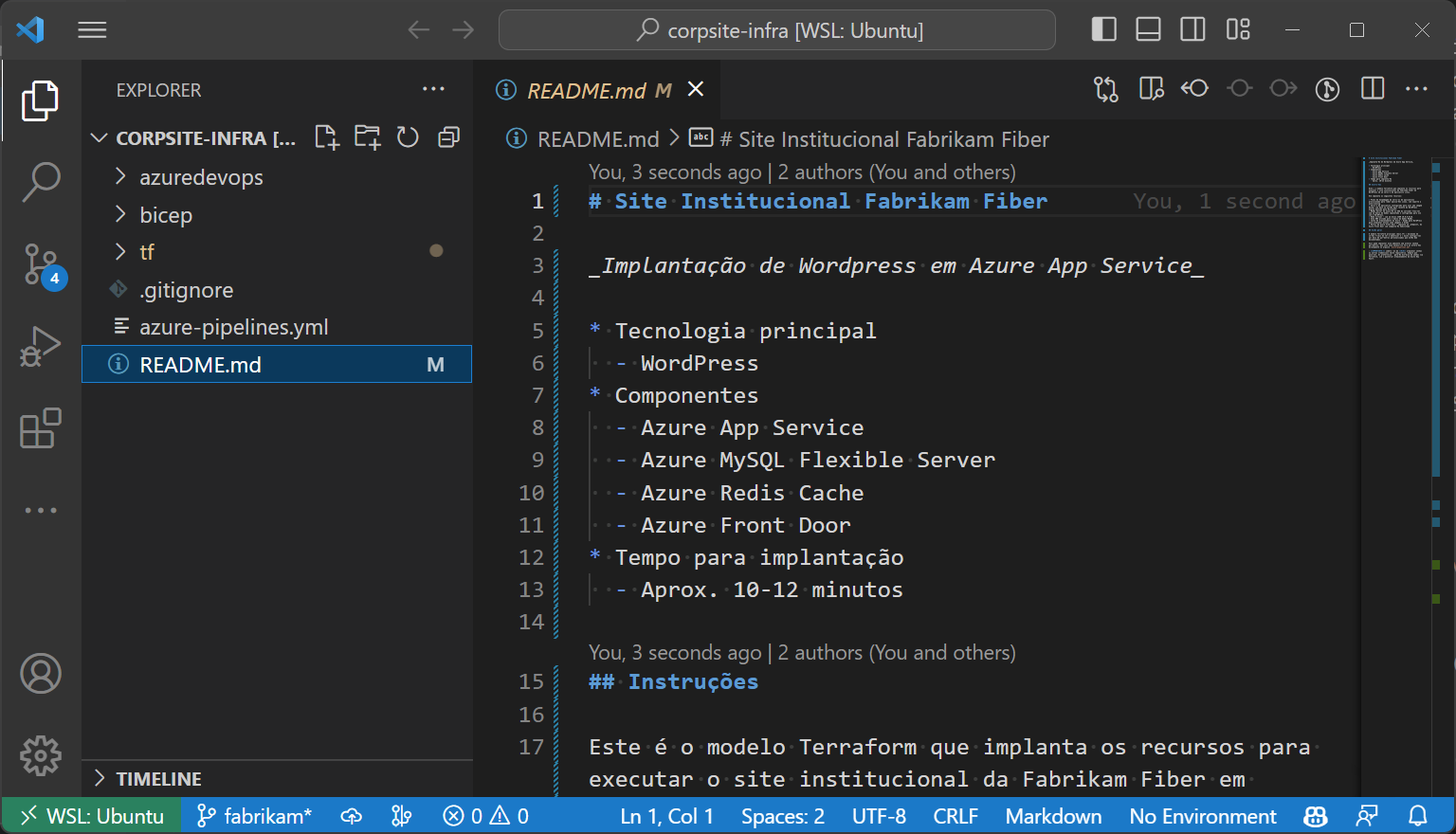
Com isso, podemos começar a examinar o processo executado pelo nosso pipeline.
Processo do pipeline
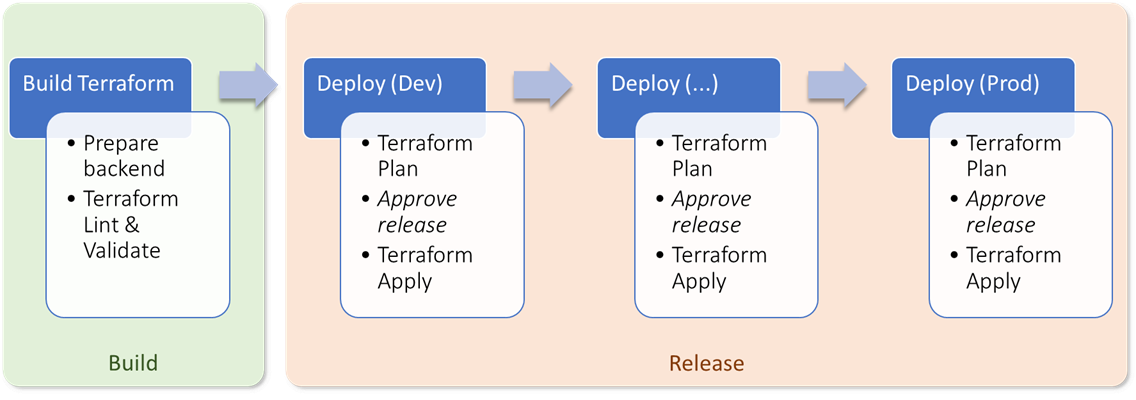
Nosso pipeline começa com um estágio de “build”, que prepara o ambiente do Terraform e valida os scripts (lint).
Na sequência, cada ambiente a ser provisionado é representado por um estágio próprio, que executa o Terraform para fazer o provisionamento. Entre os estágios de Plan e Apply, há uma aprovação manual, que permite que o usuário inspecione as mudanças antes de permitir que o Terraform execute o Apply.
Build Terraform
O primeiro estágio do pipeline é o de “build”. Este estágio prepara o ambiente de execução do Terraform e também valida o seu script. Ele é composto das seguintes etapas:
- Preparar backend
- Terraform Init
- Terraform Validate
- Terraform Lint
- Publicar artefato
Prepare backend
Para podermos executar um pipeline de Terraform, a primeira coisa que precisamos preparar é o backend - a estrutura onde o arquivo de estado (“tfstate”) do Terraform será armazenado. No caso de um ambiente no Azure, o mais comum é usar uma Storage Account para armazenar o arquivo de estado.
O problema é que, aqui, acabamos numa situação meio de “ovo ou galinha”: para criar uma Storage Account no nosso pipeline, precisamos do Terraform funcionando. Mas para ter o Terraform funcionando, precisamos da Storage Account.
É por isso que, aqui, abrimos uma pequena exceção e usamos o Bicep.
O Bicep é uma linguagem de DSL (Domain Specific Language) que permite escrever modelos de infraestrutura para o Azure. Ele é uma alternativa ao ARM Template, que é a linguagem nativa do Azure para provisionamento de recursos. A vantagem do Bicep é que ele é muito mais simples e legível que o ARM Template, além de ser mais fácil de manter e de versionar.
O que fizemos com o nosso Bicep foi criar uma Storage Account (a partir dos parâmetros passados pelo pipeline) e, em seguida, obter uma chave de acesso compartilhada (SAS) paraa essa Storage Account. Essa chave será usada pelo Terraform para armazenar o arquivo de estado.
Para executar esse Bicep, usamos o comando az deployment group create num shellscript executado a partir da task do Azure CLI:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# Break script on error
set -e
# Generate deployment name
DEPLOYMENTNAME="AzurePipelines_Bicep_$(date +%s)"
echo "# Deployment name: $DEPLOYMENTNAME"
# Create resource group (if needed)
az group create -n $TFSTATERESOURCEGROUPNAME --location $TFSTATELOCATION
# Deploy Bicep template
az deployment group create -n $DEPLOYMENTNAME -g $TFSTATERESOURCEGROUPNAME --template-file main.bicep --parameters \
storageAccountName=$TFSTATESTORAGEACCOUNTNAME \
containerName=$TFSTATECONTAINERNAME
# Get connection string for storage account
CONNSTRING=$(az deployment group show -n $DEPLOYMENTNAME -g $TFSTATERESOURCEGROUPNAME \
--query properties.outputs.connectionString.value -o tsv)
# Create output variable
echo "##vso[task.setvariable variable=TfStateConnectionString;isOutput=true,isSecret=true]$CONNSTRING"
Repare no script acima. Depois de executar nosso script Bicep (a linha com o az deployment group create), usamos o comando az deployment group show para obter a chave de acesso compartilhada (SAS) da Storage Account criada. Essa chave é armazenada numa variável de saída do pipeline, que será usada pelo Terraform posteriormente para configurar o backend.
Terraform Init
Para começar a usar o Terraform no Azure Pipelines, precisamos instalá-lo (para, entre outras coisas, especificar a versão que iremos utilizar) e então executar o comando terraform init para configurar o backend.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#.........................
- task: TerraformInstaller@0
displayName: Install Terraform ${{ parameters.TerraformVersion }}
#.........................
inputs:
terraformVersion: ${{ parameters.TerraformVersion }}
#.........................
- task: TerraformTaskV4@4
displayName: Terraform Init
#.........................
inputs:
command: init
workingDirectory: ${{ parameters.WorkingDirectory }}
backendType: azurerm
backendAzureRmStorageAccountName: ${{ parameters.TfStateStorageAccountName }}
backendAzureRmContainerName: ${{ parameters.TfStateContainerName }}
backendAzureRmKey: ${{ parameters.TfStateKeyName }}
backendAzureRmConnectionString: $(TfStateConnectionString)
Aqui você pode ver a variável TfStateConnectionString (que foi criada anteriormente pelo nosso script Bicep) sendo usada na task do Terraform para configurar o backend.
Terraform Validate
Agora estamos prontos para começar a executar o Terraform propriamente. A primeira etapa de um pipeline de CI/CD do Terraform é sempre a execução do comando Validate - afinal, não adianta nada tentar criar um ambiente com o Terraform se o script não estiver correto.
1
2
3
4
5
6
7
8
#.........................
- task: TerraformTaskV4@4
displayName: Terraform Validate
#.........................
inputs:
command: validate
workingDirectory: ${{ parameters.WorkingDirectory }}
Se estiver tudo OK com a sintaxe dos nossos scripts, podemos seguir para a etapa seguinte - o Lint.
Terraform Lint
Um “linter” é uma ferramenta de análise estática de código que ajuda a identificar erros de sintaxe e de estilo. No caso do Terraform, o linter mais usado é o TFLint. O benefício de incluir um linter no nosso pipeline é que, diferentemente do que o comando terraform validate faz, o TFLint é capaz de identificar erros de estilo e de boas práticas. Por exemplo, o TFLint é capaz de identificar se estamos usando uma versão desatualizada do Terraform, se estamos usando variáveis não declaradas, se estamos declarando variáveis que não utilizadas, se estamos usando recursos sem tags etc.
Muitas vezes, esses erros indicam problemas de lógica no nosso script. Com um linter, podemos identificar esses problemas antes mesmo de tentar executar o Terraform Plan ou o Apply, ganhando tempo no nosso processo.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#.........................
- task: CmdLine@2
displayName: Install tflint $(TfLintVersion)
#.........................
inputs:
targetType: 'inline'
script: |
cd ${AGENT_TOOLSDIRECTORY}
# export TFLINT_VERSION=${{ parameters.TfLintVersion }}
curl -s https://raw.githubusercontent.com/terraform-linters/tflint/master/install_linux.sh | bash
#.........................
- task: CmdLine@2
displayName: Run tflint
#.........................
inputs:
targetType: 'inline'
script: |
cd "${{ parameters.WorkingDir }}"
tflint --init
tflint .
Além do TFLint, aqui na CloudMotion costumamos usar também o Checkov. O Checkov é um linter específico para o Terraform que verifica se o seu código está de acordo com as melhores práticas de segurança da CIS. O Checkov é capaz de identificar, por exemplo, se você está usando uma imagem de máquina virtual desatualizada, se está usando uma porta de rede aberta para o mundo, se está usando uma política de acesso a recursos muito permissiva etc.
Ou seja, enquanto o TFLint pega problemas de estilo e de boas práticas, o Checkov pega problemas de segurança. Por isso, é uma boa ideia incluir os dois no seu pipeline.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#.........................
- task: CmdLine@2
displayName: Install checkov $(CheckovVersion)
#.........................
inputs:
targetType: 'inline'
script: |
CHECKOV_DIR=${AGENT_TOOLSDIRECTORY}/checkov
mkdir -p $CHECKOV_DIR
python3 -m venv $CHECKOV_DIR
source $CHECKOV_DIR/bin/activate
pip3 install checkov==${{ parameters.CheckovVersion }}
echo "##vso[task.prependpath]$CHECKOV_DIR/bin"
#.........................
- task: CmdLine@2
displayName: Run checkov
#.........................
inputs:
targetType: 'inline'
script: checkov --directory "${{ parameters.WorkingDir }}" --framework terraform --quiet --compact
Publicar artefato
Agora que já validamos e lintamos nosso código, podemos publicar um artefato com todo o ambiente de Terraform para serem usados no próximo estágio do pipeline.
Este é uma etapa muito útil - e, ainda assim, ignorada pela maioria dos pipelines de Terraform que já tive a oportunidade e analisar. A ideia é que, ao publicar um artefato com o ambiente de Terraform, podemos reutilizá-lo em outros pipelines, sem precisar executar o Terraform Init e o Terraform Validate novamente.
Com isso garantimos consistência (o mesmo ambiente que foi validado é o que será usado no próximo estágio) e ganhamos tempo (não precisamos executar o Terraform Init e o Terraform Validate novamente).
Para isso, basta copiar todo o conteúdo da pasta onde estão os scripts do Terraform. Dentro dessa pasta foi criada também a pasta de trabalho .tf do Terraform, onde estão - por exemplo - os arquivos dos providers que foram baixados durante o terraform init.
Agora é só colocar tudo isso num arquivo Zip que será publicado como um artefato a ser consumido na etapa de deployment:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#.........................
- task: ArchiveFiles@2
displayName: Archive Terraform files
#.........................
inputs:
rootFolderOrFile: ${{ parameters.WorkingDirectory }}
includeRootFolder: false
archiveType: tar
tarCompression: gzip
archiveFile: $(Build.ArtifactStagingDirectory)/${{ parameters.WorkingDirectory }}.tar.gz
replaceExistingArchive: true
#.........................
- task: PublishBuildArtifacts@1
displayName: Publish Terraform files as artifact
#.........................
inputs:
PathToPublish: $(Build.ArtifactStagingDirectory)
ArtifactName: ${{ parameters.WorkingDirectory }}
publishLocation: Container
Deploy
O estágio de deploy é composto de um estágio para cada ambiente a ser provisionado - ou seja, se estivermos criando um ambiente que está dividio em Desenvolvimento e Produção, teremos dois estágios no nosso pipeline. Cada estágio é composto das seguintes etapas:
- Terraform Plan
- Aprovar release
- Terraform Apply
Terraform Plan
Para poder executar a etapa de Planejamento do Terraform, é preciso primeiramente restaurar o artefato que foi publicado na etapa anterior:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#.........................
- download: current
displayName: Download Terraform files
#.........................
artifact: tf
#.........................
- task: ExtractFiles@1
displayName: Extract Terraform files
#.........................
inputs:
archiveFilePatterns: '$(Pipeline.Workspace)/tf/tf.tar.gz'
destinationFolder: '$(workingDir)'
#.........................
- task: TerraformInstaller@0
displayName: Install Terraform $(TerraformVersion)
#.........................
inputs:
terraformVersion: $(TerraformVersion)
Repare que, além das tasks de Download e de Extract(para baixar o artefato e depois descompactar o Zip localmente) foi preciso também instalar o Terraform. Isso porque já não estamos mais no mesmo agente de build onde foi executada a etapa de Build do Terraform, então é preciso preparar o ambiente novamente.
Vale lembrar que a Microsoft faz cache de ferramentas comumente utilizadas (como o Terraform), então a “instalação” é na verdade um processo bastante rápido.
Com o ambiente preparado, a próxima etapa é a seleção do Workspace. O Workspace é um conceito do Terraform que permite que você tenha vários ambientes (como Desenvolvimento, Homologação e Produção) dentro do mesmo projeto. Cada ambiente é isolado do outro, mas compartilha o mesmo código. Isso é muito útil para evitar que você tenha que duplicar o código do Terraform para cada ambiente.
1
2
3
4
5
6
7
8
9
#.........................
- task: Cmdline@2
displayName: Prepare Terraform Workspace
#.........................
inputs:
script: |
cd $(workingDir)
terraform workspace new ${{ parameters.EnvironmentName }} || terraform workspace select ${{ parameters.EnvironmentName }}
Para usar um workspace no Terraform é preciso primeiramente criá-lo (caso não exista) e então selecioná-lo. Para isso, encadeamos a execução dos dois comandos (workspace new e workspace select) usando o operador || - que significa “execute o próximo comando apenas se o anterior falhar”.
Isso é necessário porque, se o workspace já existir, o comando workspace new vai falhar - mas isso não é um problema, pois isso apenas indica que o workspace já existe e podemos seguir em frente “ativando” o workspace correspondente ao ambiente desejado.
Note que nosso pipeline tem um parâmetro chamado EnvironmentName que é usado para definir o nome do workspace. É através dele que indicamos o nome do nosso ambiente, como indicado no trecho abaixo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
#=========================
- stage: deploy_dev
displayName: Deploy (Dev)
#=========================
dependsOn: build_terraform
condition: succeeded()
jobs:
- template: azuredevops/templates/terraform-deploy.yml
parameters:
RootId: $(RootId)
RootName: $(RootName)
AppName: $(AppName)
EnvironmentName: dev
EnvironmentLocation: $(LandingZoneLocation)
EnvironmentServiceConnection: $(ServiceConnection_Dev)
ApproverEmail: $(ApproverEmail)
TerraformVersion: $(TerraformVersion)
TerraformVariables:
service_plans:
corpsite:
hosting_plan_sku : "P2v3"
workers: 1
apps:
corpsiteweb:
app_settings:
WEBSITE_NODE_DEFAULT_VERSION: 14.17.0
WEBSITE_RUN_FROM_PACKAGE: 1
Nesse trecho do nosso pipeline, você pode ver que estamos declarando nosso EnvironmentName como sendo “dev”. Para o estágio correspondente ao ambiente de produção, fazemos algo parecido.
Ah, outra coisa importante de destacar: Reparou que estamos usando um template para definir o estágio de deploy? Isso é FUNDAMENTAL para um processo sadio de automação de Terraform. Já cansei de ver pipelines que duplicavam o código de implantação em Dev e Prod. Além da inconveniência de ter de dar manutenção em mais de um lugar, isso também é um risco para o nosso ambiente, pois aumenta a chance de termos diferenças entre os ambientes.
“Isso quer dizer que os ambiente de Dev e Prod são iguais?!”
Não, pequeno gafanhoto. Não mesmo! O que isso quer dizer é que o processo - e os scripts - de Terraform são os mesmos. Tudo aquilo que muda de um ambiente para o outros - configurações de rede, tamanhos de máquinas, nomes de recursos etc. - são definidos como parâmetros do pipeline. Isso é o que veremos a seguir.
Nossa task de execução do Terraform Plan recebe todos os nossos parâmetros. Esses parâmetros são, por sua vez, passados para o Terraform através de um arquivo JSON que é gerado dentro do nosso template. No exemplo anterior, alguns dos parâmetros passados (como RootId, RootName, AppName etc.) são usados para compor o nome dos recursos que serão criados. Outros, por sua vez, são passados diretamente para o Terraform para definir os recursos que serão criados (parâmetro TerraformVariables). Já os parâmetros EnvironmentLocation e EnvironmentServiceConnection são usados para definir a localização do ambiente e a conexão com o Azure, respectivamente.
Lembra que comentei que passamos as variáveis para o Terraform usando um arquivo JSON? Esse arquivo é gerado através da conversão do parâmetro TerraformVariables em um arquivo JSON:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#.........................
- task: Cmdline@2
displayName: Generate Terraform Variables file
#.........................
inputs:
script: |
cd $(workingDir)
cat << EOF > .tfvars.json
${JSON}
EOF
cat .tfvars.json
env:
JSON: ${{ convertToJson(parameters.TerraformVariables) }}
Nós usamos a funcão convertToJson do Azure Pipelines para converter nosso parâmetro numa string em formato JSON, que por sua vez é gravada num arquivo chamado .tfvars.json. Esse arquivo é então passado para o Terraform quando fazemos a chamada do Plan:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#.........................
- task: TerraformTaskV4@4
displayName: Terraform Plan
#.........................
name: tf_plan
inputs:
command: plan
workingDirectory: $(workingDir)
environmentServiceNameAzureRm: ${{ parameters.EnvironmentServiceConnection }}
publishPlanResults: true
commandOptions: -input=false -out tf.plan -var-file=.tfvars.json
env:
TF_VAR_root_id: ${{ parameters.RootId }}
TF_VAR_root_name: ${{ parameters.RootName }}
TF_VAR_app_name: ${{ parameters.AppName }}
TF_VAR_environment_name: ${{ parameters.EnvironmentName }}
TF_VAR_environment_location: ${{ parameters.EnvironmentLocation }}
TF_VAR_terraform_version: $(TerraformVersion)
Como estamos usando templates aqui na CloudMotion, definimos que algumas variáveis são de passagem obrigatória para nosso modelo de script e, por isso, são declaradas explicitamente - RootId, RootName, AppName, EnvironmentName, EnvironmentLocation e TerraformVersion.
Todas as outras - aquelas que são específicas do tipo de recurso que será criado em nosso pipeline - são declaradas no parâmetro TerraformVariables do nosso template e passadas diretamente para o Terraform.
Aprovar release
Aqui tem mais uma “novidade”: Naturalmente queremos ter um processo de aprovação manual antes de implantar qualquer alteração em nossos ambiente. E, no Azure Pipelines, isso normalmente é feito através da utilização de Approvals and Checks.
Entretanto, quando ativamos o recurso de Aprovação para um estágio, ele é validado no início do estágio. E qual o problema disso?
O problema é que, no início do estágio, o Terraform Plan ainda não foi executado. Com isso, como alguém pode aprovar uma implantação sem saber quais serão as consequências dela? É preciso que o Plan tenha sido executado para que possamos avaliar quais recursos serão criados, alterados ou removidos.
Por isso, ao invés de usar Approvals and Checks, nós utilizamos uma task de Validação Manual, inserida entre os processos de Plan e Apply:
1
2
3
4
5
6
7
8
9
10
11
12
#.........................
- task: ManualValidation@0
displayName: Approve Deployment
#.........................
inputs:
instructions: |
Antes de aprovar a implantação, não se esqueça
de verificar se o Terraform Plan está correto.
emailRecipients: $(ApproverEmail)
timeoutInMinutes: 1440
onTimeout: reject
Assim, nosso aprovador consegue olhar o log do pipeline e examinar o resultado do Plan antes de aprovar a implantação. Caso ele aprove a implantação, o pipeline continua exatamente do mesmo ponto, onde o Terraform Apply é executado.
Terraform Apply
Agora que estamos prontos para o Apply, quero aproveitar para mostrar outro erro comum em pipelines de Terraform - e como contornamos ele aqui.
Pergunta simples: “Se o Terraform Plan indicar que não houve alterações no ambiente, posso executar o Apply?”
A resposta é mais simples ainda: “Sim, você pode. Mas por que você faria isso?!”
Afinal, se não houve nenhuma mudança detectada durante o planejamento, por que perder tempo executando o Apply? Não seria melhor simplesmente cancelar o pipeline e economizar tempo e recursos?
Entretanto, o que costumo ver é o pessoal executando os dois na sequência, sem avaliar o resultado do plano. Entretanto, o Terraform torna muito fácil evitar isso. Quando você executa o Plan, pode pedir para o Terraform indicar (através de um valor de retorno) se houve ou não alterações no ambiente. A task do Terraform, por sua vez, expõe esse valor através de uma variável de saída chamada changesPresent. Então, basta usar essa variável como uma condição para a execução do nosso deployment, como abaixo:
1
2
3
4
5
6
7
8
9
10
11
#-------------------------
- deployment: deploy_${{ parameters.EnvironmentName }}
displayName: Terraform Apply
#-------------------------
environment: ${{ parameters.RootId }}_${{ parameters.AppName }}_${{ parameters.EnvironmentLocation }}_${{ parameters.EnvironmentName }}
dependsOn: ['plan_${{ parameters.EnvironmentName }}', 'deployment_approval_${{ parameters.EnvironmentName }}']
condition: and(succeeded(), eq(dependencies.plan_${{ parameters.EnvironmentName }}.outputs['tf_plan.changesPresent'], 'true'))
strategy:
runOnce:
deploy:
Ou seja, apenas executaremos o estágio de Apply se o Plan indicar que houve alterações no ambiente (changesPresent será true). Caso contrário, o pipeline será cancelado.
Como já aprendemos a preservar o ambiente do Terraform (publicando seus arquivos na forma de artefato), a execução do Apply fica bem simples. Não preciso me preocupar com variáveis nem nada, visto que todas já foram passadas no Plan:
1
2
3
4
5
6
7
8
9
10
#.........................
- task: TerraformTaskV4@4
displayName: Terraform Apply
#.........................
inputs:
command: apply
workingDirectory: $(Build.SourcesDirectory)/tf
environmentServiceNameAzureRm: ${{ parameters.EnvironmentServiceConnection }}
commandOptions: -auto-approve -input=false tf.plan
Conclusão
E é isso! Com esse pipeline, conseguimos implantar qualquer tipo de recurso no Azure, usando o Terraform, de forma segura e confiável. E, como bônus, ainda conseguimos economizar tempo e recursos, evitando a execução desnecessária de um Apply!
Aproveite a oportunidade para explorar recursos do Azure Pipelines que você pode não usar no dia-a-dia, como os templates que mencionamos aqui e a utilização de artefatos para a passagem de arquivos entre etapas do pipeline.
Ah, outra coisa que usamos em nosso pipeline foi a funcionalidade de cache, para evitar a instalação das nossas ferramentas sempre que rodamos nosso pipeline. Isso foi especialmente importante para o Checkov, pois sua instalação é relativamente lenta. Mas isso é assunto para outro artigo!
Espero que tenham gostado e que esse artigo tenha sido útil para vocês. E, se tiverem alguma dúvida ou sugestão, não deixem de comentar aqui embaixo!
Um abraço,
Igor
02/05/2023 | Por Igor Abade V. Leite | Em Técnico | Tempo de leitura: 15 mins.


